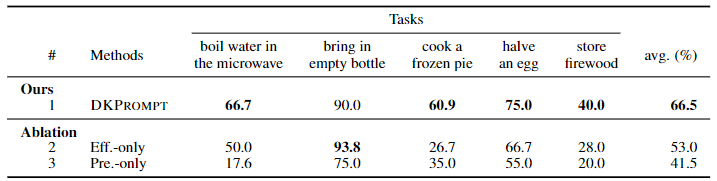
An Overview of DKPROMPT.

An overview of DKPROMPT. By simply querying the robot's current observation against the domain knowledge~(i.e., action preconditions and effects) as VQA tasks, DKPROMPT can call the classical planner to generate a new valid plan using updated world states. Note that DKPROMPT only queries about predicates. The left shows how DKPROMPT checks every precondition of the action to be executed next, and the right shows how it verifies the expected action effects are all in place after action execution. Replanning is triggered when preconditions or effects are unsatisfied after updating the planner's action knowledge.